
")



I. Introduction▲
En voilà un titre qu'il est alléchant !!!! Plus sérieusement, cet article se veut une introduction dans le monde de l'informatique décisionnelle. Ce domaine, jeune et en plein boom, constitue un des plus grands virages, à mon sens, depuis la vulgarisation des systèmes informatiques de gestion en entreprise. Les avancées technologiques ainsi que les exigences du marché ont rendu ce domaine incontournable chez les analystes, décideurs et développeurs. Tout le monde veut se mettre au BI, et tout le monde à raison. La valeur ajoutée que peut apporter un environnement de BI dans une entreprise est simplement stupéfiante : Wal-Mart, une grosse entreprise de distribution grand public a prouvé cela en démarrant un projet de BI très peu après la création de l'entreprise. Résultat, l'entreprise est indétrônable, sa gestion interne est parfaite, la gestion des stocks impeccable, et sa capacité à prévoir les tendances et habitudes des consommateurs nous met à la fois en admiration et en crainte : ils sont capables de prévoir ce que le client moyen va acheter avant même qu'il ne rentre dans un magasin… Cet article, pas du tout technique je précise, essaye de donner un contexte et une définition au terme « informatique décisionnelle », qui, bien que très utilisé, reste très flou pour beaucoup d'entre nous. Nous parlerons d'abord de la genèse de ce phénomène, puis nous distinguerons la différence entre le mode opérationnel et décisionnel dans une entreprise.
Note : l'article suivant continuera dans cette lancée en parlant de l'architecture des environnements décisionnels.
II. Historique et genèse▲
Pour mieux comprendre un phénomène, rien ne vaut le retour à la source. Suivez le guide ! Intéressons-nous au besoin en information des entreprises du début des années 70 à nos jours.
II-A. Le commencement▲
Début des années 70. L'informatique reste un « petit joujou » que les patrons précurseurs s'offrent. Pas à cause de la rentabilité du produit ou son efficacité, mais parce que ça amuse, ça fait penser au futur… Le besoin en information, à cette époque, commençait à apparaître, car la concurrence commence à faire rage. On commence à comprendre : celui qui détient l'information détient le marché. Toute la gestion des entreprises se faisait à la main, jusqu'au jour où on entendit parler d'une machine nommée ordinateur et qui pouvait faire des calculs automatiques et les sauvegarder dans leur mémoire. Le boom commence, les entreprises s'informatisent et le besoin en information est assouvi. Les patrons peuvent connaître les résultats de leur activité journalière, et même mensuelle dans certains cas.
II-B. Les Data Centers▲
Nous sommes maintenant dans les années 80, les entreprises continuent à s'informatiser, mais les plus malignes commencent à accumuler beaucoup de données. Les Data Centers naissent. Des départements informatiques gérant des années et des années de données de production. Mais plus l'entreprise accumule des données, plus les analystes et les patrons veulent faire des analyses dessus. C'est normal, car c'est en fouillant dans les données qu'on peut savoir ce qui peut être amélioré dans l'entreprise. Manque de technologie et de maturité oblige, seul le service informatique peut créer des rapports à partir des sources de données. Un ballet incessant entre la direction et le département informatique commence. En effet, le processus de recherche d'information implique fatalement un processus de type question - réponse - question. Chaque réponse entraîne un processus de réflexion qui, à son tour, amène une nouvelle question, et puisqu'a cette époque une question implique une demande de rapport. Nos pauvres informaticiens se retrouvent très rapidement surchargés. Et les systèmes de production aussi.
II-C. Le Reporting▲
Devant le constat que la demande en information ne pourra jamais être pleinement satisfaite si le département informatique est tout le temps sollicité. Les informaticiens ont pensé des logiciels de génération de rapports. Ces logiciels (principalement à base de menus) contiendraient des rapports paramétrables que les utilisateurs pourront interroger à leur guise. La solution semble régler le problème, mais deux effets de bord vont apparaître suite à la naissance des systèmes de reporting :
- la demande en information ne cessant de croître, les systèmes se retrouvent surchargés : après l'apparition des outils de reporting, les utilisateurs se sont sentis plus indépendants. Ils commencèrent à interroger la base de production sur une base régulière, ce qui entraînât une forte charge de travail sur les serveurs, qui, rappelons-le, ne sont pas faits pour créer des rapports complexes, mais pour faire des opérations élémentaires dans la vie d'une entreprise (ajouter un client, une facture, consulter les dernières commandes d'un client, etc.). Cette surcharge fut réparée par des mises à jour matérielles sur les serveurs, mais cela revenait à traiter l'effet et non la cause ;
- la demande en information du marché rendait les décideurs insatisfaits des systèmes de reporting : en effet, au début des années 90, l'insatisfaction à l'égard des informaticiens était grande. Car ces derniers étaient censés, avec les technologies de l'époque, pouvoir assouvir la soif de connaissance de l'entreprise. Mais les systèmes de reporting donnaient des rapports trop « grand public », cela ne faisait que titiller encore plus leur curiosité.
II-D. Le début de la maturité. L'informatique décisionnelle▲
Devant l'état actuel (rappelons que nous sommes dans les années 90). Chercheurs en informatique et professionnels se sont penchés sur cette question clé qui est : comment aider les décideurs à prendre des décisions ? Il fallait un environnement, et non un système, car la seule façon d'assouvir leur soif d'information est de leur permettre de fouiller eux même dans les données pour trouver ce qu'ils cherchent. Car la plupart du temps, les analystes ne savent pas ce qu'ils cherchent, leur travail est d'analyser l'entreprise pour l'améliorer, ils peuvent avoir des pistes, des doutes, des points de départ, mais jamais rien de concret. Un processus de input - output ne serait donc pas pertinent pour eux. OK, il faut un environnement, mais que doit avoir cet environnement pour aider les décideurs à décider :
- simple : les décideurs ne sont pas des gourous en informatique. L'environnement doit donc être assez simple et intuitif pour être manipulé par des non-informaticiens ;
- rapide : le temps de nos décideurs est précieux. Pas question d'avoir une réponse des jours après l'avoir posé ;
- gros volume de données : la prise de décision au niveau des analystes et des patrons se fait à un très haut niveau d'abstraction. On analyse la tendance des ventes sur les trois dernières années pour déterminer des actions à entreprendre. L'environnement doit pouvoir gérer de très gros volumes de données ;
- indépendant du système de production : plus question de faire planter le système de production à cause d'une requête faite par un analyste ;
- pour un membre restreint d'utilisateurs : en effet, la prise de décision n'est la responsabilité que de quelques personnes dans l'entreprise. Le sommet de la pyramide ;
- fiable et hétérogène : l'environnement doit pouvoir compiler toutes les sources de données que possède l'entreprise. La conséquence est qu'un risque d'erreur dans les données peut se produire. Il s'agit de minimiser ce risque. La non-fiabilité impliquera forcément le manque de confiance.
À partir de ces caractéristiques, des concepts, outils, logiciels se sont formés et articulés autour de ce nouveau domaine qui est l'informatique décisionnelle. Une nouvelle façon de concevoir les choses était née. On veut maintenant séparer le décisionnel du transactionnel. On a compris que les systèmes d'opération sont faits pour opérer et non pour prendre des décisions stratégiques. Le BI est né.
III. Les deux mondes : décisionnel et opérationnel▲
Avant même de commencer à s'intéresser aux concepts du BI, il faut en capter l'essence, la philosophie. Cela ne fera que nous donner une meilleure vision et un meilleur sens de l'analyse. Expliquons d'abord chacun des deux mondes, puis synthétisons.
III-A. Le monde opérationnel▲
Ce sont les tâches, quotidiennes, répétitives et atomiques qui sont effectuées par les employés de l'entreprise pour lui permettre d'avoir une activité et donc de survivre. Le traitement d'une commande, l'édition d'une facture, l'emballage d'un produit, le suivi d'un colis ou la consignation d'une réclamation sont des taches nécessaires à la vie d'une entreprise. On parle d'opération quand on parle de ce type d'actions. Les systèmes informatiques opérationnels (OLTP pour OnLine Transactional Processing) sont faits pour assister les opérations d'une entreprise, ce sont des systèmes de gestion ou de production qui relatent la vie de l'entreprise (les opérations) dans un environnement informatique, plus restreint, mieux gérable et plus flexible. Les caractéristiques des systèmes opérationnels sont :
- Grand public : les OLTP sont des aides à l'opération, ils sont donc destinés à toute personne participant à la vie quotidienne de l'entreprise. Donc tous les employés de l'entreprise. Les décideurs sont exclus du groupe, car ils participent à un niveau plus élevé que la gestion quotidienne ;
- Données atomiques : on entre un produit, une ligne de commande, une facture. Ce sont des éléments avec un grain très fin ;
- Extrêmement rapides : dans un système de gestion de pannes d'une centrale nucléaire, il ne faudrait pas que le système nous annonce une panne critique 30 minutes après qu'elle s'est produite… ;
- Fermés : on ne laisse pas la place à l'improvisation dans les OLTP, les choix sont restreints, les utilisateurs sont guidés dans le processus ;
- Petite volumétrie des données : les systèmes de gestion ne gèrent pas des Téra Octets de données. Ces systèmes s'intéressent à ce qui se passe maintenant ;
- Transactionnels : les OLTP fonctionnent en utilisant le principe de transaction ;
- Lecture, écriture et modification des données : dans un OLTP on peut ajouter de l'information, en supprimer si elle n'est pas utile pour la production et la modifier s'il existe des erreurs ;
- Projets comportant peu de risques : les projets de systèmes OLTP sont maintenant bien rodés, les fonctionnalités et les besoins évidents, il y'a moins de risque d'échecs ;
- Fragmentés : on entend par ici décentralisés. Sauf dans le cas des ERP, on trouvera des systèmes pour la gestion des ressources humaines, des systèmes pour la production, des CRM, des systèmes de facturation, etc. ;
- Hétérogènes : les systèmes OLTP sont souvent des systèmes disparates en termes de technologie utilisée. Il n'est pas rare d'avoir dans la même entreprise un système de gestion avec une base de données MySQL et développé en Java et un système de production avec une BD MSSQL et développé en .NET.
III-B. Le monde décisionnel▲
Il peut paraître évident de dire que le monde décisionnel est le contraire du monde opérationnel. Je préfère dire que l'un chapeaute l'autre. Tandis que les OLTP font rouler l'entreprise, l'informatique décisionnelle voit rouler l'entreprise et agit en fonction de ce qu'elle voit. L'informatique décisionnelle est l'ensemble des méthodes, moyens et outils informatiques utilisés pour piloter une entreprise et aider à la décision. On parle aussi de systèmes d'aide à la décision et de Business Intelligence. Tandis que les systèmes opérationnels s'intéressent à ce qui se passe tout de suite, les environnements d'aide à la décision s'intéressent aux tendances, aux moyennes, aux écarts types des principaux indicateurs de bonne santé de l'entreprise, et ce, à travers les mois ou les années (car une tendance se dégage avec le temps). Le monde décisionnel analyse, prédit, conseille, regarde de haut les données de l'entreprise pour mieux apprécier l'ensemble de l'activité. Les caractéristiques suivantes, et qui sont communes à tout produit décisionnel, se dégagent d'elles-mêmes :
- Petit nombre d'utilisateurs : l'aide à la décision stratégique est le lot de quelques personnes dans l'entreprise (décideurs, patrons) ;
- Données générales et détaillées : on s'intéresse ici aux chiffres par mois, par année, par groupe de produit, etc. Les décideurs n'ont pas intérêt à voir la commande de tel ou tel client. Ils veulent voir l'ensemble de l'activité. Par contre, les analystes ont tout intérêt à pouvoir creuser dans les données pour trouver des fraudeurs par exemple ;
- Rapidité suggérée : il est clair que plus c'est rapide et mieux c'est ! Mais dans la prise de décision stratégique, on ne calcule pas à la seconde. Un décideur peut bien attendre quelques heures pour avoir une information très complexe à créer. Mais dans la plupart des cas, les temps de réponse doivent être calculés en secondes ;
- Ouverts : contrairement au monde opérationnel, on laisse libre cours à la curiosité des utilisateurs, les environnements de BI doivent permettre d'accéder le plus simplement possible aux données et d'en faire tout ce qu'on veut ! ;
- Gros volumes de données : les environnements de BI doivent regrouper toutes les données de l'entreprise. De la ligne de commande au chiffre d'affaires annuel. Des années et des années d'accumulation de données génèrent des Gigas Octets qui doivent être gérés par les environnements de BI ;
- Non transactionnels : pas de processus rigide ici. L'utilisateur doit pouvoir commencer une analyse, revenir en arrière, démarrer une autre analyse en parallèle, envoyer un résultat à un collègue pour qu'il puisse creuser une autre piste… ;
- Données en lecture seule : pas de perte de données dans le monde décisionnel. On ne supprime jamais des données, on archive. Si le prix d'un produit change, on veut garder trace de cela ;
- Projets très risqués : et c'est la le hic. En 2002, 40 % des projets de BI ont échoué. La principale raison est le manque d'engagements de la part de la direction et le manque de connaissances dans le domaine. Il y'aura un article à ce sujet ;
- Centralisés : toutes les données sont regroupées en un seul point. Une même source pour tout le monde.
IV. Synthèse▲
Pour ceux qui auraient la flemme de lire ce qu'il y a plus haut (je vous conseille de lire, car ceci n'est qu'un résumé). Voici les points essentiels qu'a traités cet article.
- Le BI est le résultat d'une évolution des besoins de la part des décideurs et analystes des entreprises. Le but du BI est d'aider à la décision et de permettre des analystes précises, complexes et de grande envergure dans les entreprises.
- Les systèmes opérationnels font tourner l'entreprise. Ils assistent la production et la vie quotidienne de celle-ci.
- Les systèmes décisionnels voient tourner l'entreprise. Ils permettent de générer de la connaissance à partir des données, et donc, d'aider à faire des décisions stratégiques.
- Les différences entre le monde opérationnel et décisionnel peuvent être résumées ainsi :
|
Décisionnel |
Opérationnel |
|---|---|
|
Gros volumes de données à gérer. |
Petits volumes de données à gérer. |
|
Nombre d'utilisateurs restreint (décideurs, analystes). |
Utilisé par toute l'entreprise. |
|
Processus ouverts pour permettre la génération de connaissance. |
Processus fermés, transactionnels, le but est de donner le moins de marge de manœuvre possible. |
|
Données en lecture seule. |
Données en lecture - Écriture. |
|
Rapidité moyenne comparée aux systèmes opérationnels. |
Réponses très rapides. |
|
Niveau de granularité très grand (on peut avoir des résumés sur ce qui c'est passé durant les 10 dernières années par exemple). |
Niveau de granularité fin. |
|
Centralisés (on veut avoir toutes les données de l'entreprise dans une seule structure). |
Décentralisés. |
V. Architecture d'un environnement décisionnel▲
Après avoir parlé de ce qu'était le BI, intéressons-nous à comment avoir un environnement de BI dans son entreprise. C'est bien beau la théorie, mais il faut du concret maintenant. Comment pouvoir gérer de gros volumes de données, quels schémas de données sont assez simples pour pouvoir être assimilés par des non-informaticiens, comment permettre des analyses en temps réel en mode « intuitif ». C'est à toutes ces questions que la suite de cet article va tenter de répondre.
V-A. Sur quoi se base le BI ? (les concepts)▲
L'intelligence d'affaires se base sur un concept clé qui est l'entrepôt de données ou le Data Warehouse. En résumé, c'est une architecture de données (comme une base de données relationnelle classique) qui permet, de par sa simplicité, de représenter et de rendre disponible un gros volume de données. Pour plus de renseignements sur ce qu'est un entrepôt de données, suivez le lienDW. C'est donc autour de cette grosse masse de données organisée très simplement (en étoile ou en flocon) que viennent graviter les différents composants d'une architecture décisionnelle.
V-B. Qu'est-ce qu'une architecture de BI ?▲
Une architecture de BI est un ensemble de concepts, outils, méthodes, et technologies (logicielles et matérielles) qui, une fois mis en relation, permettent de créer de la connaissance et répondre aux besoins stratégiques de l'entreprise (dans le meilleur de cas :)). Une architecture de BI peut être comparée à la structure d'une maison, c'est l'ensemble des poutres, murs, tuyauterie, etc. qui permettront à une famille de vivre ou à une école de fonctionner. Il est important de comprendre ce concept d'architecture et de savoir le différentier des autres termes tels que environnement, système, logiciel, etc. Pour une meilleure communication dans vos futurs projets :)
V-C. Quels sont les composants d'une architecture décisionnelle ?▲
Nous entrons dans le vif du sujet. Qu'est-ce qui fait une architecture décisionnelle. Énonçons cela point par point.
V-C-1. Entrepôt de données▲
C'est le concept clé comme nous l'avons précédemment expliquéentrepot de données. Une définition pourrait être qu'un Data Warehouse est l'ensemble des données historiées, nettoyées, valides, complètes et cohérentes d'une entreprise. Organisées de telle façon à ce que des non-informaticiens puissent en comprendre la structure et l'exploiter, sans l'intervention d'un informaticien. Les grands du BI (Inmon, Kimball) définissent un entrepôt de données par ses caractéristiques.
- Orienté métier : c'est-à-dire que dans un entrepôt de données, les informations sont organisées par fonction dans l'entreprise (comptabilité, stocks, ventes, etc.).
- En lecture seule : c'est le point crucial, on ne supprime JAMAIS des données d'un entrepôt puisque sa raison d'exister est de conserver tout changement.
- Organisé en axes : les données sont organisées en axes d'analyses (dimensions) et objets d'analyse (fait). Une dimension est un axe avec lequel nous allons analyser un phénomène dans l'entreprise (fait).
- Intégrées : tous les systèmes stockant des informations dans l'entrepôt sont des sources potentielles de données. Feuilles de calculs, systèmes de production, feuilles de travail, etc. L'entrepôt intégrera ces éléments pour former une vision unique de l'activité de l'entreprise.
- Différents niveaux de granularité : l'entrepôt doit être capable de livrer des informations aussi détaillées (ligne de facture) que générales (chiffre d'affaires pour une année), et ce de la façon la plus transparente possible.
Un prochain tuto expliquera dans le détail la façon de concevoir un entrepôt de données.
V-C-2. ETL▲
On entend par la : Extraction, Transformation, Loading. C'est un système par lequel vont passer toutes les données des systèmes opérationnels avant d'arriver dans la forme souhaitée dans l'entrepôt. Imaginez une sorte de moulinette par laquelle vous ferez passer toutes les données de votre entreprise. Les données en sortie (passées à la moulinette) seront nettoyées, purifiées (les gros morceaux seront mis de côté), contextualisées (les données des différents systèmes s'homogénéiseront) et prêtes à être reçues dans l'entrepôt. Le système d'ETL est la partie la plus importante d'un projet décisionnel. Car c'est avec l'ETL que les systèmes seront mis en relation, les erreurs détectées, les calculs complexes effectués, etc. On peut dire que la solidité d'un ETL détermine la viabilité du projet.
À cette étape, vous pouvez considérer l'entrepôt et l'ETL comme des boites noires. Le but de cet article est d'expliquer l'architecture des environnements de BI, les différents composants auront leurs articles propres (il y a beaucoup à dire :)).
V-C-3. Serveur d'analyse▲
C'est un serveur, qui servira pour l'analyse… Non, en vérité c'est dans cette partie que nous introduirons le terme « OLAP », acronyme de OnLine Analytical Processing. Un serveur d'analyse est un moyen permettant aux analystes et décideurs de naviguer, forer, découvrir les données de l'entrepôt. C'est un concert de technologies (logicielles surtout) permettant de rendre incroyablement malléable un entrepôt de données. Avec un serveur d'analyse, un serveur OLAP par exemple, un analyste pourrait très bien faire tous les croisements qu'il veut : le chiffre d'affaires par client, par produit, par zone géographique, par fournisseur. Ainsi, sans qu'il y ait de rapport préformaté, les utilisateurs joueront dans les données comme bon leur semble. Là est l'aspect tant attrayant et vendeur des solutions BI. Si l'on dit à un analyste « tu pourras jouer comme tu veux dans les données de ton entreprise », soyez surs qu'il vous suivra.
Au moment où cet article est écrit, la technologie la plus efficace pour effectuer des analyses à partir d'entrepôts de données est bel et bien OLAP. Cela mérite quelques approfondissements sur le sujet.
Ami Wikipedia définit OLAP comme : les bases de données multidimensionnelles (aussi appelées cubes ou hypercubes) destinées à des analyses complexes sur ses données. Ce terme a été défini par Ted Codd en 1993 au travers de 12 règles que doit respecter une base de données si elle veut adhérer au concept OLAP.
- Vue conceptuelle multidimensionnelle
- Transparence
- Accessibilité
- Constance des temps de réponse
- Architecture client-serveur
- Indépendance des dimensions
- Gestion des matrices creuses
- Accès multiutilisateurs
- Pas de restrictions sur les opérations inter et intra dimensions
- Manipulation des données aisée
- Simplicité des rapports
- Nombre illimité de dimensions et nombre illimité d'éléments sur les dimensions
Ça a l'air bien scientifique comme ça, mais rassurez vous tout va devenir plus clair au fil des pages de documentation que vous lirez :)
En résumé, OLAP est un mode de stockage optimisé pour les analyses de gros volumes de données, à l'instar des bases de données relationnelles en 3e forme normale qui, elles, sont optimisées pour la gestion transactionnelle d'un petit volume de données (beaucoup d'écritures, en mode concurrent, beaucoup d'accès disques). OLAP se base sur les concepts de dimensions et de faits pour créer des représentations multidimensionnelles des données, c'est-à-dire que les faits sont calculés par rapport à des axes (comme en trigonométrie). L'appellation « cube » est utilisée pour faciliter la visualisation du concept. Imaginez un cube (trois dimensions), qui représenterait les ventes selon trois axes : produit, client et date par exemple. Imaginez maintenant les opérations trigonométriques que l'on pourrait faire dessus :
- Découper une tranche du cube : reviendrait à faire une analyse par rapport à un seul axe ;
- Changer l'échelle des axes pour mieux voir : c'est-à-dire zoomer ou dé zoomer sur le cube pour en apprécier le détail ou la généralité ;
- extraire une partie du cube : donc focuser sur une sélection de données ;
- etc.
Toutes ces opérations, qui sont de la plus grande utilité pour n'importe quel analyste, font la force et la popularité de cette technologie. OLAP est sans conteste la meilleure solution, pour le moment, pour faire de l'analyse stratégique sur les données d'une entreprise.
En attendant mon prochain article sur OLAP, je vous invite à voir les démos des principales entreprises œuvrant dans le domaine (Microsoft, Oracle, IBM, Business Objects, Cognos, Pentaho) pour une meilleure compréhension de la technologie, et ne vous noyez pas dans le bla bla commercial :)
V-C-4. Outils « end-user »▲
Ce sont les outils et logiciels que les utilisateurs auront pour manipuler les données et profiter des services offerts par l'entrepôt de données et le serveur d'analyse. Ces outils doivent impérativement être aussi ouverts que la philosophie et les principes du BI. Pas de menus complexes, pas de multi choix, l'utopie serait une feuille blanche, les outils d'exploitation et les données (on se rapproche de plus en plus de cette utopie). Les avancées technologiques permettent maintenant d'avoir des outils très simples et très puissants à la portée de tout le monde. Voyez par exemple les tableaux de bord d'entreprise, qui sont un exemple d'outils end-user BI, ou les serveurs de rapports, ou les tableurs utilisant OLAP, etc.
VI. Synthèse▲
Une image valant mille mots, je vous propose ce schéma d'architecture BI, tiré du site de quadra informatique, et qui montre l'orchestration des éléments décrits ci-dessus pour former un environnement de BI. Il est à noter que la plupart (pour ne pas dire tous) des fabricants d'outils BI se basent sur cette architecture :
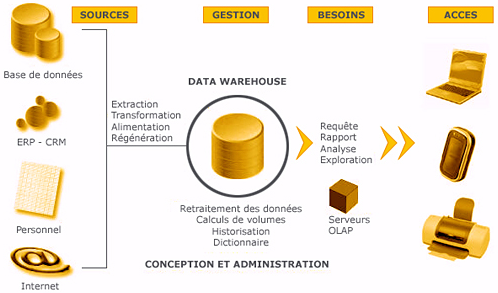
Les articles suivants s'intéresseront dans le détail à chaque élément de l'architecture, leur conception et leur mise en œuvre. À suivre…
VII. Conclusion▲
En ayant lu cet article, et quelques documents des grands du BI (Bill Inmon, Ralph Kimball, etc.) vous pourrez avoir la vision nécessaire pour entrer dans cette discipline passionnante qu'est l'informatique décisionnelle. Mes prochains articles entreront dans le vif du sujet : méthodes de conception d'entrepôt de données, topologies d'ETL, création de cubes avec Sql Server 2005, etc. Entretemps je vous invite à parcourir ces livres pour un approfondissement de ce qui a été traité dans cet article.
Remerciements▲
Je voudrais remercier Immobilis, RideKick et Adrien Artero pour leurs conseils avisés et leurs relectures attentives. Merci les gars !